
Le aziende possono trovarsi in difficoltà in ogni momento della loro “vita tecnologica”. Una ricerca mostra che oltre il 50% delle aziende non è in grado di superare un grave disastro trovandosi impreparata e senza un adeguato sistema di protezione dei dati. È fondamentale essere consapevoli della propria infrastruttura IT e comprendere quali misure di sicurezza delle informazioni si possono adottare per ridurre i danni causati da un disastro e ripristinare rapidamente l’operatività.
In questo articolo propongo alcuni elementi essenziali da includere nel proprio Disaster Recovery al fine di renderlo efficace ed efficiente.
Cos’è il Disaster Recovery?
Il Disaster Recovery è l’approccio adottato da un’azienda che consente di anticipare, pianificare e riprendere nel minor tempo possibile la propria operatività a seguito di incidenti di qualsiasi tipo, come ad esempio:
- calamità naturali (es: terremoti o uragani);
- situazioni meno estese da un punto di vista geografico quali incendi, cedimento di solai, allagamenti, etc;
- guasto dell'attrezzatura o dell'infrastruttura, come un'interruzione di corrente o un'avaria del disco rigido;
- eventi provocati dall'uomo, come l’eliminazione accidentale di dati o la perdita di apparecchiature;
- attacchi informatici da parte di malintenzionati.
Scopri di più >> Cybercrime: i numeri degli attacchi hacker e dei furti dati
Un piano di Disaster Recovery consente alle aziende di rispondere rapidamente a un disastro e intraprendere azioni immediate per ridurre i danni e “ripartire” con le attività il prima possibile. In genere, un piano di Disaster Recovery include:
- lo staff addetto alle procedure di emergenza;
- le risorse IT ritenute essenziali ed i relativi RPO e RTO che l’azienda desidera applicare;
- gli strumenti o le tecnologie che dovrebbero essere utilizzati per il recupero dei dati;
- un team di Disaster Recovery, le informazioni di contatto e le procedure di comunicazione (es. chi dovrebbe essere informato in caso di disastro);
- un Piano di Rientro con la procedura da seguire per poter riportare i servizi presso la server room principale.
Alcune caratteristiche principali di un programma di Disaster Recovery
Ecco alcuni elementi da considerare nella stesura del piano e nel processo di Disaster Recovery per garantire la ripresa del business in caso di incidenti.
Conoscere le minacce
E’ importante scoprire la storia della propria azienda, del settore e della regione. Questo permetterà di mappare le minacce, dalle più alle meno probabili, compreso il grado di gravità ed estensione. I parametri da tenere in considerazione dovrebbero includere calamità naturali, eventi geopolitici, guasti alle infrastrutture come server, connessioni Internet o software, inclusi attacchi informatici che hanno maggior possibilità di impattare sull’attività della propria realtà aziendale.
Inoltre, l’azienda si deve assicurare che il piano sia efficace contro tutte o almeno le più significative minacce. Se necessario, è importante sviluppare diversi piani di Disaster Recovery o sezioni separate all'interno del piano, ognuna dedicata a specifiche tipologie di incidente.
Conoscere e discriminare le risorse
E’ importante avere consapevolezza: il proprio team stila in primis un elenco delle risorse/servizi ritenuti importanti per le normali attività dell’azienda. Nel mondo IT, ciò include apparecchiature di rete, server, workstation, software, servizi cloud, dispositivi mobili e altro ancora. Una volta stilata la lista, la si divide in:
- risorse fondamentali di cui l’azienda non può fare a meno, ad esempio un server di posta elettronica, l’ERP, MES, etc.;
- risorse importanti che possono ostacolare seriamente alcune attività, ad esempio il server della reportistica o il server per gli accessi;
- altre risorse che non hanno un impatto importante sull'attività, ad esempio un sistema di test, un sistema ricreativo utilizzato dai dipendenti durante la pausa pranzo, un proiettore.
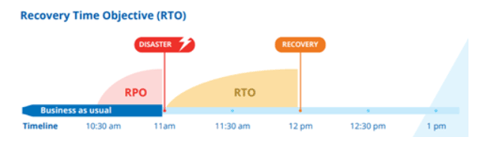
L’azienda definisce il proprio Recovery Time Objective (RTO) per le risorse fondamentali stabilendo che periodo di inattività può sostenere. Un esempio potrebbe essere rappresentato dal quantificare il danno subito se il proprio sito di e-commerce sia irraggiungibile. Alcune società possono essere in grado di sostenere un giorno o due di inattività e riprendere poi le normali operazioni, a condizione che non vi siano perdite di dati. Ciò dipende da vari fattori: le dimensioni aziendali, l’estensione del disastro, etc.
In termini puramente accademici, la definizione dell'RTO è la seguente: il tempo massimo che dovrà trascorrere dal momento in cui viene dichiarato il disastro al momento in cui i sistemi torneranno “up and running”, riportando l’azienda in uno stato di operatività (anche quest’ultima stabilità con il business).
Replicare i dati
Un punto critico di quasi tutti i piani di Disaster Recovery è quello relativo alla replica dei dati. Mentre molte aziende pianificano backup periodici, per scopi di Disaster Recovery, l'approccio preferito è quello di replicare continuamente (o ad intervalli ristretti) i dati su un altro sistema. I dati possono essere replicati su:
- On-Site Cold Storage: un dispositivo di backup all'interno del data center;
- On-Site Warm Backup: un'unità operativa ridondante nel data center, ad esempio un server secondario;
- Off-Site Cold Storage: un dispositivo di backup in un data center remoto o un cloud storage con latenza elevata, che comporta un ritardo o un costo aggiuntivo per recuperare i dati (es. vaulting nastri LTO o NAS);
- Off-Site Warm Backup: un'unità operativa ridondante in un data center remoto o un cloud storage a bassa latenza, che consente l'accesso immediato ai dati (es. una linea dedicata con un data center secondario di proprietà o terzo, che permetta una replica “in linea” su un sistema “gemello”). In questo specifico caso entrano in gioco alcune tecnologie da tenere in considerazione come ad esempio la deduplica dei dati, il throughput della linea e le politiche di traffic shaping.
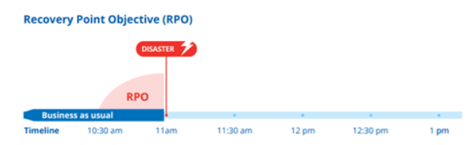
L'archiviazione locale (il classico backup) è più soggetto ad incidenti ma offre un RTO più breve. Ciò consente, data la frequenza di esecuzione delle operazioni di backup, di migliorare notevolmente il Recovery Point Objective (RPO). Ciò sta a significare che eventuali dati persi sarebbero minimi o addirittura nulli. Per completezza, l’RPO rappresenta la quantità di dati che andranno persi (espressa in minuti o ore) che l’azienda è in grado di sostenere. Praticamente definisce il tempo trascorso dall’ultimo backup valido fino al momento del disastro: la quantità di dati generata dai sistemi aziendali tra i due momenti sarà molto probabilmente persa.
Test di backup e ripristino dei servizi
Proprio come i sistemi aziendali possono danneggiarsi in caso di disastro, così possono farlo anche i backup. Ci sono molte storie di cronaca in merito ad organizzazioni che disponevano di un sistema di backup ma hanno scoperto troppo tardi che non funzionava correttamente. Un problema di configurazione, un errore del software o un guasto dell'apparecchiatura possono rendere inutili i backup e non si potrà mai sapere a meno che non si verifichino situazioni estreme.
Una parte inseparabile di qualsiasi piano di Disaster Recovery è verificare che i dati vengano replicati correttamente e che sia possibile ripristinarli nel sito di destinazione. Questi test devono essere eseguiti una tantum durante la configurazione degli apparati dedicati al Disaster Recovery ed essere ripetuti periodicamente per garantire che il "giro del fumo" funzioni correttamente (stesso concetto, con tempistiche magari differenti vale per i normali backup eseguiti in sede).
Vi sono anche altri parametri da tenere in considerazione quando si definisce un piano. Ecco un breve accenno qui di seguito:
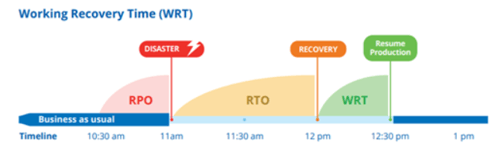
- WRT: rappresenta la quantità di tempo di cui ha bisogno il team IT/ICT per far tornare in una situazione di operatività gli utenti finali, al termine del semplice e puro ripristino dei dati aziendali.
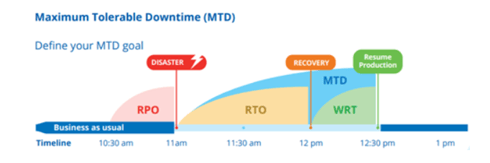
- MTD: il down time massimo tollerabile/accettabile dall’azienda rappresentato dal punto in cui è stato dichiarato il disastro ed il momento in cui gli utenti tornano in uno stato di normale operatività/produttività.
Replica e proteggi i dati senza sforzo con Metisoft
Il nostro Systems Solutions Competence Center è organizzato per aiutarti il tutto il processo di creazione, test e manutenzione di un piano di Disaster Recovery. Si parte dalla valutazione dei sistemi, reti, server, virtualizzazione, archiviazione, backup e ripristino, team, applicazioni, procedure, dati o funzioni aziendali essenziali per le operazioni e attività quotidiane.
Siamo il partner giusto per evitare che la tua azienda possa trovarsi in situazioni più o meno bloccanti. I nostri consulenti sanno come scegliere le migliori strategie e sviluppare piani di Disaster Recovery per anticipare e/o mitigare i danni. Contattaci ora per una consulenza gratuita.
